Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
ECCV 2024 Workshop @ Milano, Italy, Sep 30th Monday
Street view videos generated with MagicDrive.
Track 2: Corner Case Scene Generation
This track focuses on improving the capabilities of diffusion models to create multi-view street scene videos that are consistent with 3D geometric scene descriptors, including the Bird's Eye View (BEV) maps and 3D LiDAR bounding boxes. Building on MagicDrive for controllable 3D video generation, this track aims to advance scene generation for autonomous driving, ensuring better consistency, higher resolution, and longer duration.
🏆 Winners
| Rank | Team | Authors | Affiliations | Links |
|---|---|---|---|---|
| 1st | LiAuto-AD | Junpeng Jiang, Gangyi Hong, Lijun Zhou, Enhui Ma, Hengtong Hu, xia zhou, Jie Xiang, Fan Liu, Kaicheng Yu, Haiyang Sun, Kun Zhan, Peng Jia, Miao Zhang | Harbin Institute of Technology (Shenzhen), Li Auto Inc., Tsinghua University, Westlake University, National University of Singapore |
[Report] [Slide] [Video] |
| 2nd | DreamForge | Jianbiao Mei, Yukai Ma, Xuemeng Yang, Licheng Wen, Tiantian Wei, Min Dou, Botian Shi, Yong Liu | Zhejiang University, Shanghai Artificial Intelligence Laboratory, Technical University of Munich |
[Report] [Slide] [Video] |
| 3rd | Seven | Zhiying Du, Zhen Xing | Shanghai Key Lab of Intell. Info. Processing, School of CS, Fudan University |
[Report] [Slide] [Video] |
Updates and Notifications
- [20240816] We have sent emails to the teams that have advanced to round 2. Congratulations and thank you for participation! Please submit your report before 23:59 AoE on August 23, 2024. The submission link is: [OpenReview Submission Site].
- [20240810] If participants fail to submit for round 2 before the deadline, we will use the submission for round 1 in our human evaluation. As we require editing results in round 2, participants with round 2 submissions will rank higher than those without it.
- [20240730] To verify the qualification for your round 2 submission, please include a readme file for long-video generations to tell us which short video they correspond to.
- [20240723] Please include both round 1 and round 2 results in your submission. There is no separate submission for round 2.
Challenge Progress
Leaderboard
*Update on Dec. 17th, 2025.
Task and Baseline
Task: In this challenge, participants should train a controllable multi-view street view video generation model, which is the same as MagicDrive. The generated video should accurately reflect the control signals from BEV road map, 3D bounding boxes and test description of weather and time-of-day. We will evaluate the generated videos from generation quality and controllability (detailed below).
Baseline: MagicDrive.
Please checkout to video branch for video generation. To help the
participants to start, we have provided a 16-frame version with config and
pre-trained weights. Enjoy!
Data Description
We use the nuScenes dataset as the testbench for this challenge. nuScenes is a commonly used autonomous driving dataset that provides 6 camera view at 12Hz convering 360-degree of the scenes. Following the official train/val split, teams should use the 750 scenes for training and 150 scenes from validation for evaluation and submission only.
Detailed Rules and Guidelines
Data Preparation
To start, participants should download the original data from the nuScenes official site. Please note to download camera sweeps (12Hz), only keyframes (2Hz) is not enough. The provided codebase is based on mmdet3d, which re-organize the meta data for loading. We provide the following data for to facilitate participants:
| Name | Description | OneDrive |
|---|---|---|
data/nuscenes_mmdet3d_2
|
mmdet3d meta data for nuScenes (only keyframes, only for perception models) | link |
data/nuscenes/interp_12Hz_trainval anddata/nuscenes_mmdet3d-12Hz/*interp*.pkl
|
interpolated 12Hz annotation and mmdet3d meta data (for both training and testing) | link |
data/nuscenes/advanced_12Hz_trainval anddata/nuscenes_mmdet3d-12Hz/*advanced*.pkl
|
interpolated 12Hz annotation with advanced method from ASAP, and mmdet3d meta data (optional for training) | link |
nuscenes_interp_12Hz_infos_track2_eval.pkl
|
sampled from "interp", for 1st round evaluation and submission | link |
nuscenes_interp_12Hz_infos_track2_eval_long.pkl
|
sampled from "interp", for 2nd round evaluation and submission | link |
Since the annotation is only at 2Hz, we provide the interpolated annotations from ASAP in the table above. After download the files above, you should be also to organize them as described in Datasets.
If you find any resources unavailable, or need other resource to run our baseline, please do not hasitate to let us know!
Training
Please setup your python environment as described in Environment Setup and prepare the pretrained weights from Pretrained Weights. Then start your training/testing as described in Train MagicDrive-t and Video Generation.
To run our baseline, please download our pretrained model from OneDrive
Note: Our baseline use the config from rawbox_mv2.0t_0.4.3.
Participate
Register. Before submission, please register your team information here.
Each team can only have one registration, and each registration is valid for one single track. Note that your Team Name will be used as reference for evaluation latter.
Submission. For submission, we require each team to:
-
generate 4 16-frame videos for each of the 150 scenes from the
eval-standardset (600 videos). -
generate 3 any-length videos for each of the 3 scenes from the
eval-longset (9 videos).
nuscenes_interp_12Hz_infos_track2_eval.pkl to
generate 16-frame videos for submission. If your model is capable of longer video generation, please
use nuscenes_interp_12Hz_infos_track2_eval_long.pkl, and add clips of the first 16 frames
in your submission to round 1. In other words, For the 9 long videos, one of the three should contains
the exact content in the 600 videos for the same scene (see Evaluation for more details).
Videos should be generated starting from the first frame of each scene.
Videos (mp4 files)
should be compressed with the provided scripts and renamed accordingly. Please
check more details in readme. We also provide a
submission sample to let participants better understand the submission format.
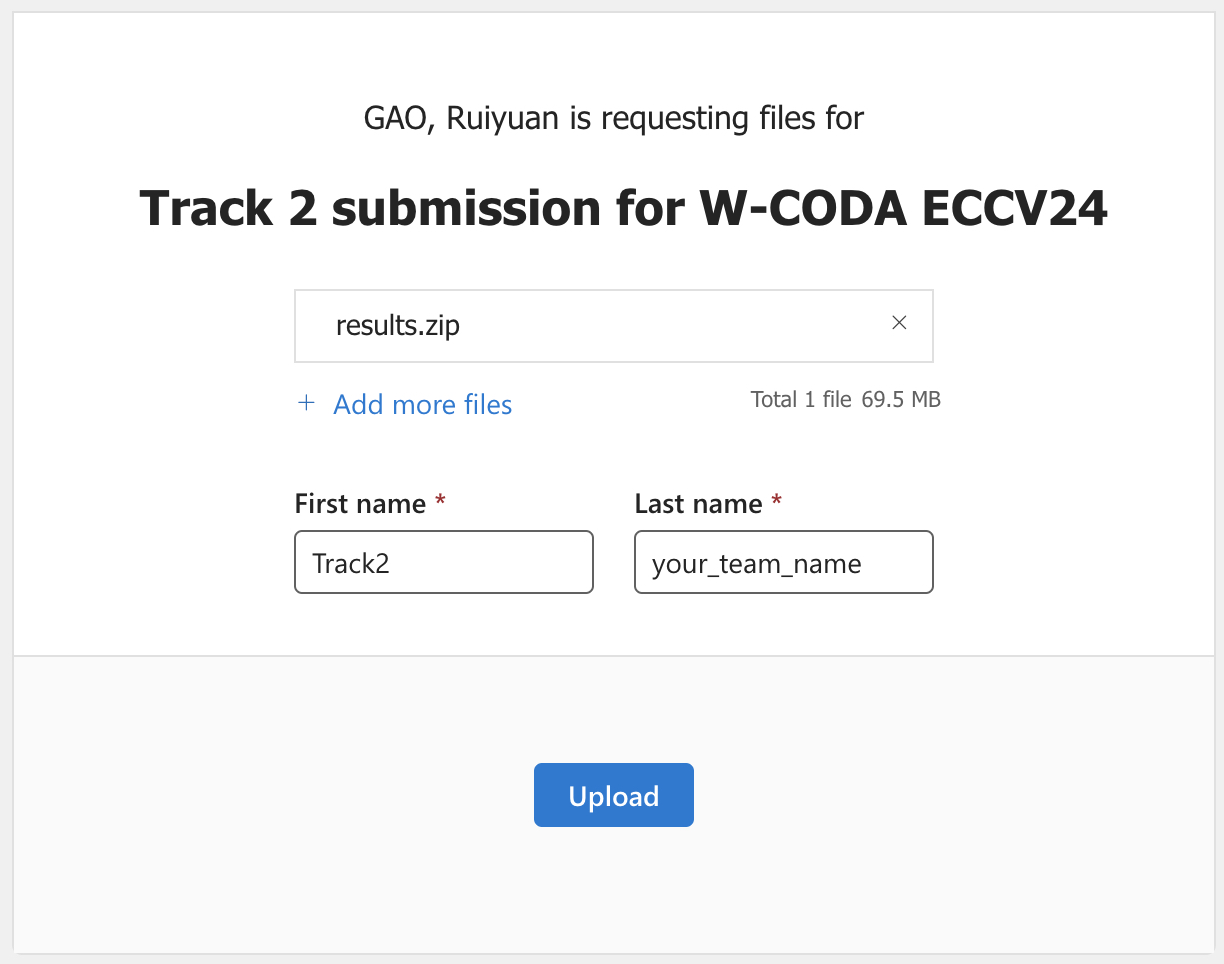
Please upload your submission via the Upload link on OneDrive. Enter your Track and Team Name and click Upload (Our server gathers results every 5 minutes. Please refrain from uploading too frequently).
Please strictly follow the naming format below when submitting, otherwise your submission will be considered invalid!- File name: must be
results.zip, instead ofanswer.zip,sample_answer.zip, etc. - First name: must be
Track2, instead ofTrack 2,Track_2, etc. - Last name: must be your
full Team namein the registration form, which will be used as the key to match your registration information. You must not separate your Team name into different parts! - Any violation will result in an error when dealing with the submission file, and thus, considered as invalid.
Evaluation
There will be 2 rounds for evaluation (Please include both rounds in one submission file. There is NO separated submission for round2.):
- 1st round (Jun. 15-Aug. 15): score evaluation for 16-frame videos
- 2nd round (Aug. 15): human evaluation for long videos
For the 1st round: we evaluate the generated videos by generation quality and controllability with three metrics:
- FVD: commonly used metric for video generation quality evaluation.
- mAP: from 3D object detection with BEVFormer. As defined by nuScenes.
- mIoU: from BEV segmentation with BEVFormer. As defined by their paper.
For the 2nd round: each team is required to submit 9 videos (12-fps) from 3 scenes, each with 3 different conditions (sunny day, rainy day, and night). Our human evaluators will rank each video from quality and controllability. In general, we prefer long videos with high resolutions.
We only consider the top-10 participants from the 1st round and use the submitted long videos for the 2nd round.
Note that, we require results generated from one single model for both rounds. To ensure this, the "sunny day" video in the 2nd round should contains the exact content submitted for the 1st round (i.e., the 16-frame can be clipped from longer videos).
General Rules
- To ensure fairness, the top-3 winners are required to submit a technical report.
- Each entry is required to be associated to a team and its affiliation (all members of one team must register as one).
- Using multiple accounts to increase the number of submissions is strictly prohibited.
- Results should follow the correct format and must be uploaded to the submission to OneDrive (refer to the Submission section), which, otherwise, will not be considered as valid submissions. Detailed information about how results will be evaluated is provided in the Evaluation section.
- The best entry of each team is public in the leaderboard, and we will update once a week.
- The organizer reserves the absolute right to disqualify entries that are incomplete, illegible, late, or violating the rules.
Awards
Participants with the most successful and innovative entries will be invited to present at this workshop and receive awards. A 1,000 USD cash prize will be awarded to the top team, while the 2nd and 3rd will be awarded with 800 USD and 600 USD separately.
Contact
To contact the organizers please use w-coda2024@googlegroups.com