Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
ECCV 2024 Workshop @ Milano, Italy, Sep 30th Monday
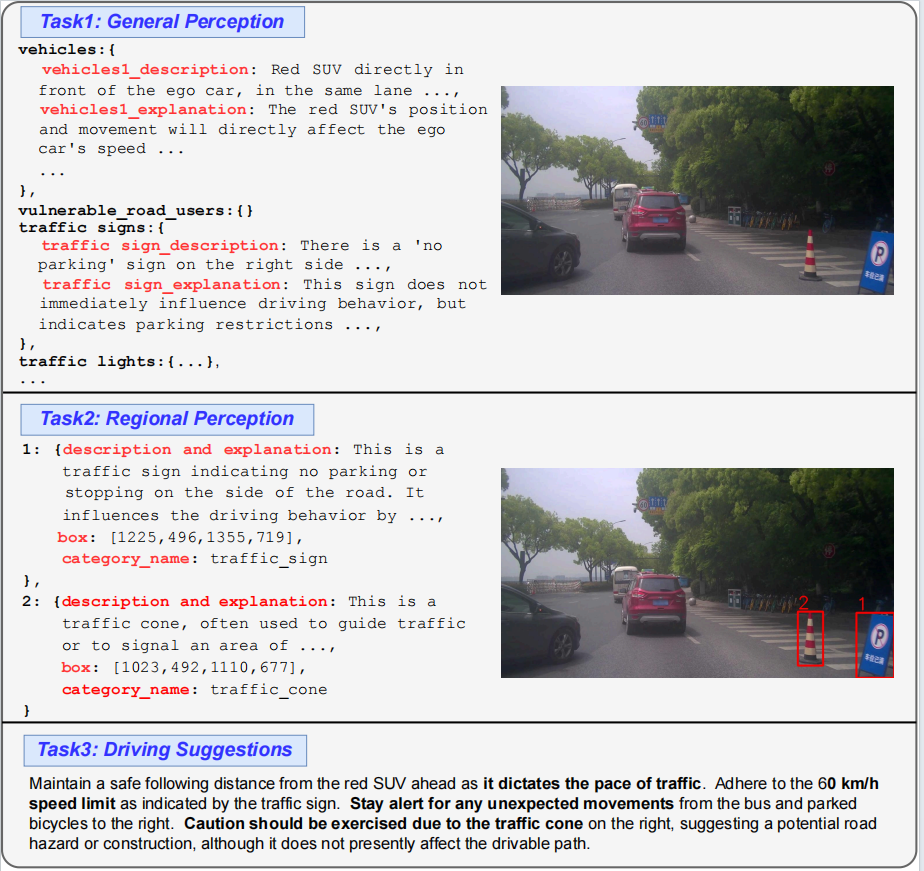

Visual perception and comprehension data samples from CODA-LM.
Track 1: Corner Case Scene Understanding
This competition is dedicated to enhancing multimodal perception and comprehension capabilities of MLLMs for autonomous driving, focusing on the global scene understanding, local area reasoning, and actionable navigation. With our CODA-LM dataset, constructed from CODA dataset and including ~10K images with the corresponding textual descriptions covering global driving scenarios, detailed analyses of corner cases, and future driving recommendation, this competition seeks to promote the development of more reliable and interpretable autonomous driving agents.
🏆 Winners
| Rank | Team | Authors | Affiliations | Links |
|---|---|---|---|---|
| 1st | llmforad | Ying Xue, Haiming Zhang, Yiyao Zhu, Wending Zhou, Shuguang Cui, Zhen Li | The Chinese University of Hong Kong (Shenzhen), Hong Kong University of Science and Technology |
[Report] [Slide] [Video] |
| 2nd | OpenDriver | Zihao Wang, Xueyi Li | Peking University |
[Report] [Slide] [Video] |
| 3rd | NexusAD | Mengjingcheng Mo, Jingxin Wang, Like Wang, Haosheng Chen, Changjun Gu, Jiaxu Leng, Xinbo Gao | Chongqing University of Posts and Telecommunications |
[Report] [Slide] [Video] |
Announcement
- [2024.09.01] The verified Best-of-all-rounds leaderboard and Top-3 winners have been released!
- [2024.08.17] The Best-of-all-rounds leaderboard has been released! Note the leaderboard is temporal, waiting for verification. Thanks for all participants!
- [2024.08.15] Frequently asked questions we received:
- Q: Is model ensemble allowed?
A: Yes, model ensemble is allowed as long as results are automatically generated bya single modelpipeline consisting of multiple LVLMs without human intervention. Using diffrerent model pipelines for different tasks are forbidden. - Q: How to deal with multi-registration?
A: All submissions of the teams performing multi-registrtion will be considered illegal and disgarded. - Q: How to deal with prompt attack on GPT judges?
A: Thank you for your notice. We will conduct human verification for the top3 submissions to prevent this problem. - Q: How to deal with reproductivity?
A: We require competition winners to provide technical reports, and we encourage submissions for codes and checkpoints. If legal problems on Intellectual Property exist, at least an API to access the models is required.
- Q: Is model ensemble allowed?
- [2024.08.06] The final score would be the optimal historical score. No need to worry, and make good use of the remaining evaluation rounds :).
- [2024.08.03] We find potential
multi-registrationof team members from the same team. As emphasized in the General Rules, using multiple accounts to increase the number of submissions is strictly prohibited for the W-CODA competitons. - [2024.07.21] To clarify, we expect
a single modelto deal with all three tasks simultaneously. Submissions utilizing different models for different tasks will be considered illegal. - [2024.07.15] We have noticed for the
regional perceptiontask, one can access each object's ground truthcategory nameby comparing the annotations of CODA-LM and CODA datasets. Although it isnot intended by design, here we confirm that it isallowed, especially considering the primary goal of regional perception is to evaluate the capability of LVLMs in describing the given objects and why they affect self-driving in natural languages. We make this announcement to let every participant know about that for fairness consideration.
Challenge Progress
Leaderboard (Best of All Rounds)
We have removed team submissions violating the competition rules.
Task Description
General Perception. The foundational aspect of the general perception task lies in the comprehensive understanding of key entities within driving scenes, including the appearance, location, and the reasons they influence driving. Given a first-view road driving scene, MLLMs are required not only to describe all the potential road obstacles in the traffic scenes but also to provide explanations about why they would affect the driving decisions. We primarily focus on seven categories of obstacles, including vehicles, vulnerable road users (VRUs), traffic cones, traffic lights, traffic signs, barriers, and miscellaneous.
Region Perception. This task measures the MLLMs' capability to understand corner objects when provided with specific bounding boxes, followed by describing these objects and explaining why they might affect self-driving behavior. Note that for region perception, there are no constraints on how to use bounding boxes in MLLMs. Any possible encoding leading to better performance is feasible. We provide an example by visualizing the bounding boxes on images with red rectangles here for reference.
Driving Suggestions. This task aims to evaluate MLLMs' capability in formulating driving advice in the autonomous driving domain. This task is closely related to the planning process of autonomous driving, requiring MLLMs to provide optimal driving suggestions for the ego car after correctly perceiving the general and regional aspects of the current driving environment.
Data Description
Training. CODA-LM is a real-world multimodal autonomous driving dataset. Constructed on CODA dataset, CODA-LM contains high-quality annotations for general perception, region perception, and driving suggestions. The training dataset contains 4884 samples, with a validation set with 4384 samples optionally for training. For more details, please refer to the arxiv report and dataset website.
Besides CODA-LM, any external training resources are all allowed, which, however, should be discussed in technical reports.
Evaluation. CODA-LM test set, containing 500 samples, is used for our evaluation. For each of the three tasks, we follow the official evaluation protocols of CODA-LM and calculate a GPT-Score separately using a GPT-4 judge, with the Final-Score as the average.
$$\text{Final-Score}=
\frac{1}{3}(\text{GPT-Score}_{\text{General Perception}} + \text{GPT-Score}_{\text{Region Perception}} + \text{GPT-Score}_{\text{Driving Suggestions}})
$$
Download. Check the official Github Repo of CODA-LM for more details.
Terms of Use. CODA-LM dataset is released only for academic research, which is free to researchers from educational or research institutions for non-commercial purposes. When downloading the dataset you agree not to reproduce, duplicate, copy, sell, trade, resell or exploit for any commercial purposes, any portion of the images and any portion of derived data. For the full terms of use information, please refer to CODA/term of use website.
Submission
To submit your results, you must strictly complete the following steps, otherwise your submissions will not be considered valid.
- For the first time, register your team information here. Each team can only have one registration, and each registration is valid for one single track. Note that your
Team Namewill be used as reference for evaluation latter. - Download CODA-LM, and convert annotations into basic VQA formats via this script. After conversion, you will have three jsonl files (
general_perception.jsonl,region_perception.jsonl,driving_suggestion.jsonl) under$CODA_ROOT/Test/vqa_anno, all in the following formats:
{"question_id": 0, "image": test/images/0001.jpg, "question": <str>}
{"question_id": 1, "image": test/images/0012.jpg, "question": <str>}
{"question_id": 2, "image": test/images/0013.jpg, "question": <str>}
...
answer key. You must not modify the contents of question_id, image and question, which are essential for evaluation. Note for region perception, even if you are encouraged to utilize different bbox encodings, you still need to maintain contents of the three keys. Your results should be like:
{"question_id": 0, "image": test/images/0001.jpg, "question": <str>, "answer": <str>}
{"question_id": 1, "image": test/images/0012.jpg, "question": <str>, "answer": <str>}
{"question_id": 2, "image": test/images/0013.jpg, "question": <str>, "answer": <str>}
...
general_perception_answer.jsonl,
region_perception_answer.jsonl,
driving_suggestion_answer.jsonl, zip them in
results.zip, and submit via OneDrive.
To better understand the submission format, we also provide an
example submission here.
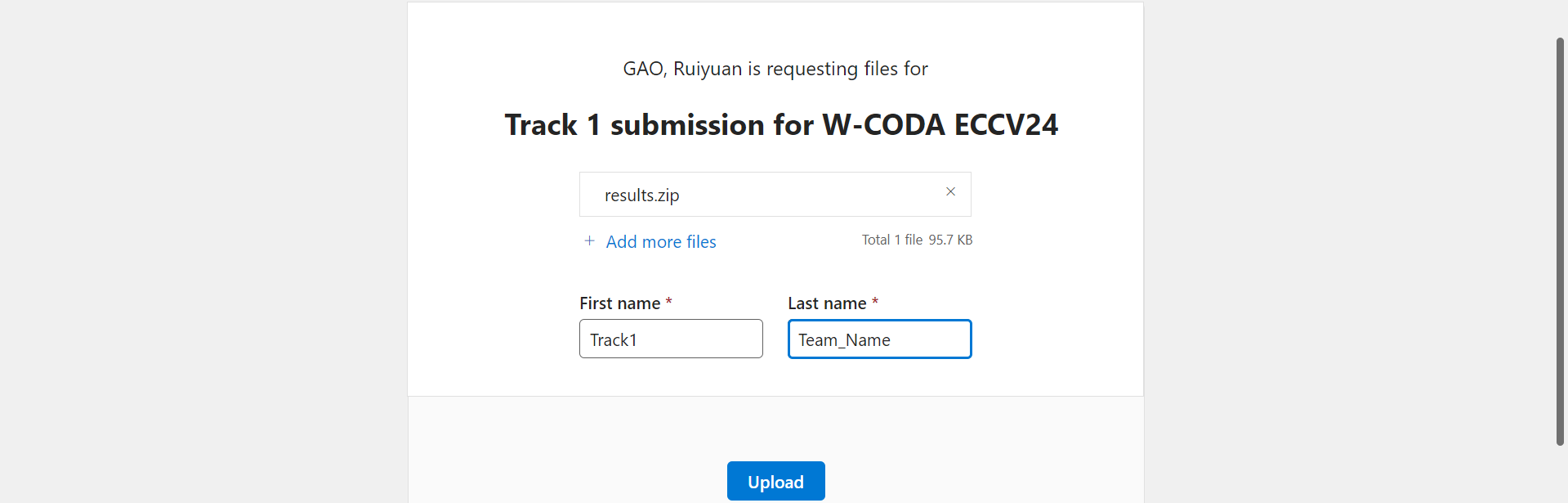
Enter your Track and Team Name and
click Upload (Our server gathers results every 5 minutes. Please refrain from uploading too frequently).- File name: must be
results.zip, instead ofanswer.zip,sample_answer.zip, etc. - First name: must be
Track1, instead ofTrack 1,Track_1, etc. - Last name: must be your
full Team namein the registration form, which will be used as the key to match your registration information. You must not separate your Team name into different parts! - File structure: your submission should only contain the three
jsonlfiles. You must not create any new folders, especially for Mac users on the__MACOSXdirectory. - Any violation will result in an error when dealing with the submission file, and thus, considered as invalid.
General Rules
- To ensure fairness, the Top-3 winners are required to submit a technical report for re-productivity verification.
- Each entry is required to be associated to a team and its affiliation (all members of one team must register as one).
- Using multiple accounts to increase the number of submissions is strictly prohibited.
- Results should follow the correct format and be submitted following the instructions, which, otherwise, will not be considered as valid submissions. Detailed information is provided on the Submission section.
- The best entry of each team is public in the leaderboard at all time.
- The organizer reserves the absolute right to disqualify entries that are incomplete, illegible, late, or violating the rules.
Awards
Participants with the most successful and innovative entries will be invited to present at this workshop and receive awards. A 1,000 USD cash prize will be awarded to the top team, while the 2nd and 3rd will be awarded with 800 USD and 600 USD separately.
Contact
To contact the organizers please use w-coda2024@googlegroups.com